





 分公司
分公司連續(xù)六年蟬聯(lián)中國互聯(lián)網(wǎng)百強(qiáng),集團(tuán)下設(shè)73家分公司,遍布全國16個(gè)省46個(gè)城市
聯(lián)系我們龍采科技集團(tuán)有限責(zé)任公司(鞍山)
http://www.maoxiangyi.cn/
龍采科技集團(tuán)有限責(zé)任公司(齊齊哈爾)
http://www.longcai0452.com/
龍采科技集團(tuán)有限責(zé)任公司(牡丹江)
http://www.longcai0453.com/
龍采科技集團(tuán)有限責(zé)任公司(佳木斯)
http://www.longcai0454.com
龍采科技集團(tuán)有限責(zé)任公司(綏化)
http://www.longcai0455.com/
龍采科技集團(tuán)有限責(zé)任公司(雞西)
http://www.longcai0467.com/
龍采科技集團(tuán)有限責(zé)任公司(大慶)
http://www.longcai0459.com/
龍采科技集團(tuán)有限責(zé)任公司(大連總部)
http://www.longcai0411.com/
龍采科技集團(tuán)有限責(zé)任公司(營口)
http://www.longcai0417.com/
龍采科技集團(tuán)有限責(zé)任公司(盤錦)
http://www.longcai0427.com/
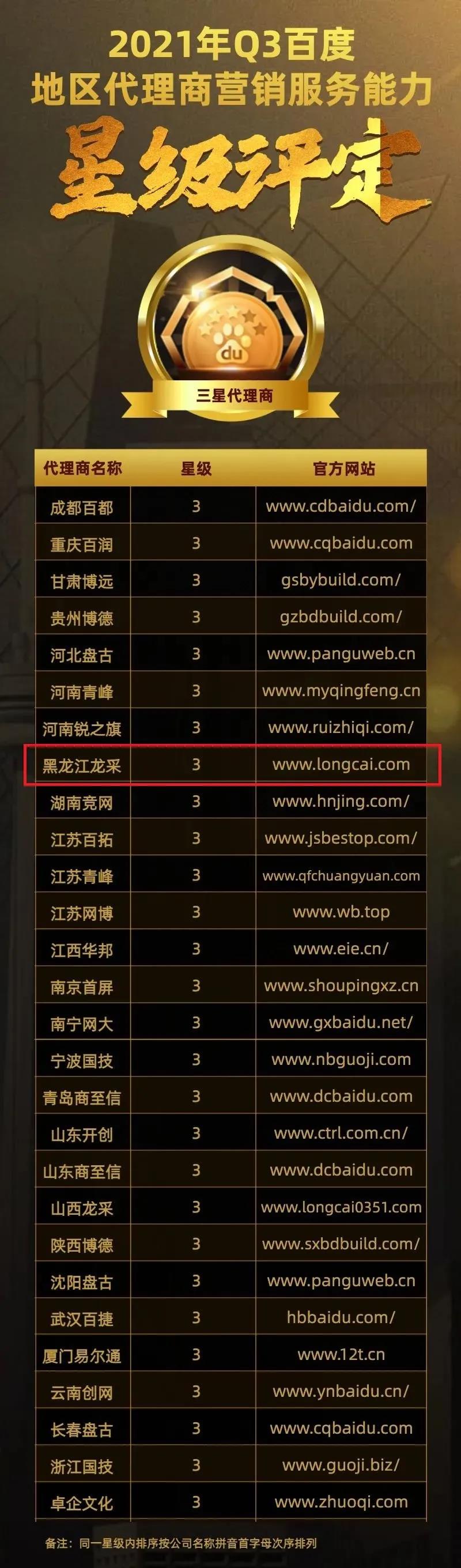
龍采科技集團(tuán)有限責(zé)任公司(黑龍江總部)
http://www.longcai.com
龍采科技集團(tuán)有限責(zé)任公司(遼陽)
http://www.longcai0419.com/
龍采科技集團(tuán)有限責(zé)任公司(阜新)
http://www.longcai0418.com/
龍采科技集團(tuán)有限責(zé)任公司(山西總部)
http://www.longcai0351.com
龍采科技集團(tuán)有限責(zé)任公司(運(yùn)城)
http://www.longcai0359.com/
龍采科技集團(tuán)有限責(zé)任公司(晉中)
http://www.longcai0354.com/
龍采科技集團(tuán)有限責(zé)任公司(陽泉)
http://www.longcai0353.com/
龍采科技集團(tuán)有限責(zé)任公司(大同)
http://www.longcai0352.com/
龍采科技集團(tuán)有限責(zé)任公司(忻州)
http://www.longcai0350.com/
龍采科技集團(tuán)有限責(zé)任公司(長治)
http://www.longcai0355.com/
龍采科技集團(tuán)有限責(zé)任公司(臨汾)
http://www.longcai0357.com/
龍采科技集團(tuán)有限責(zé)任公司(晉城)
http://www.longcai0356.com/
龍采科技集團(tuán)有限責(zé)任公司(朔州)
http://www.longcai0349.com/
龍采科技集團(tuán)有限責(zé)任公司(呂梁)
http://www.longcai0358.com/
龍采科技集團(tuán)有限責(zé)任公司(沈陽)
http://www.longcai024.com/
龍采科技集團(tuán)有限責(zé)任公司(長春)
http://www.cclongcai.com/
龍采科技集團(tuán)有限責(zé)任公司(石家莊)
http://www.longcai0311.com/
龍采科技集團(tuán)有限責(zé)任公司(青島)
http://www.qdlongcai.cn/
龍采科技集團(tuán)有限責(zé)任公司(山東)
http://www.longcai0531.com
龍采科技集團(tuán)有限責(zé)任公司(武漢)
http://www.longcai027.com
龍采科技集團(tuán)有限責(zé)任公司(南昌)
http://www.longcai0791.com
龍采科技集團(tuán)有限責(zé)任公司(上海)
http://www.longcai021.cn
龍采科技集團(tuán)有限責(zé)任公司(南京)
http://www.longcai025.com
 分公司
分公司連續(xù)六年蟬聯(lián)中國互聯(lián)網(wǎng)百強(qiáng),集團(tuán)下設(shè)73家分公司,遍布全國16個(gè)省46個(gè)城市
聯(lián)系我們龍采科技集團(tuán)有限責(zé)任公司(鞍山)
http://www.maoxiangyi.cn/
龍采科技集團(tuán)有限責(zé)任公司(齊齊哈爾)
http://www.longcai0452.com/
龍采科技集團(tuán)有限責(zé)任公司(牡丹江)
http://www.longcai0453.com/
龍采科技集團(tuán)有限責(zé)任公司(佳木斯)
http://www.longcai0454.com
龍采科技集團(tuán)有限責(zé)任公司(綏化)
http://www.longcai0455.com/
龍采科技集團(tuán)有限責(zé)任公司(雞西)
http://www.longcai0467.com/
龍采科技集團(tuán)有限責(zé)任公司(大慶)
http://www.longcai0459.com/
龍采科技集團(tuán)有限責(zé)任公司(大連總部)
http://www.longcai0411.com/
龍采科技集團(tuán)有限責(zé)任公司(營口)
http://www.longcai0417.com/
龍采科技集團(tuán)有限責(zé)任公司(盤錦)
http://www.longcai0427.com/
龍采科技集團(tuán)有限責(zé)任公司(黑龍江總部)
http://www.longcai.com
龍采科技集團(tuán)有限責(zé)任公司(遼陽)
http://www.longcai0419.com/
龍采科技集團(tuán)有限責(zé)任公司(阜新)
http://www.longcai0418.com/
龍采科技集團(tuán)有限責(zé)任公司(山西總部)
http://www.longcai0351.com
龍采科技集團(tuán)有限責(zé)任公司(運(yùn)城)
http://www.longcai0359.com/
龍采科技集團(tuán)有限責(zé)任公司(晉中)
http://www.longcai0354.com/
龍采科技集團(tuán)有限責(zé)任公司(陽泉)
http://www.longcai0353.com/
龍采科技集團(tuán)有限責(zé)任公司(大同)
http://www.longcai0352.com/
龍采科技集團(tuán)有限責(zé)任公司(忻州)
http://www.longcai0350.com/
龍采科技集團(tuán)有限責(zé)任公司(長治)
http://www.longcai0355.com/
龍采科技集團(tuán)有限責(zé)任公司(臨汾)
http://www.longcai0357.com/
龍采科技集團(tuán)有限責(zé)任公司(晉城)
http://www.longcai0356.com/
龍采科技集團(tuán)有限責(zé)任公司(朔州)
http://www.longcai0349.com/
龍采科技集團(tuán)有限責(zé)任公司(呂梁)
http://www.longcai0358.com/
龍采科技集團(tuán)有限責(zé)任公司(沈陽)
http://www.longcai024.com/
龍采科技集團(tuán)有限責(zé)任公司(長春)
http://www.cclongcai.com/
龍采科技集團(tuán)有限責(zé)任公司(石家莊)
http://www.longcai0311.com/
龍采科技集團(tuán)有限責(zé)任公司(青島)
http://www.qdlongcai.cn/
龍采科技集團(tuán)有限責(zé)任公司(山東)
http://www.longcai0531.com
龍采科技集團(tuán)有限責(zé)任公司(武漢)
http://www.longcai027.com
龍采科技集團(tuán)有限責(zé)任公司(南昌)
http://www.longcai0791.com
龍采科技集團(tuán)有限責(zé)任公司(上海)
http://www.longcai021.cn
龍采科技集團(tuán)有限責(zé)任公司(南京)
http://www.longcai025.com












































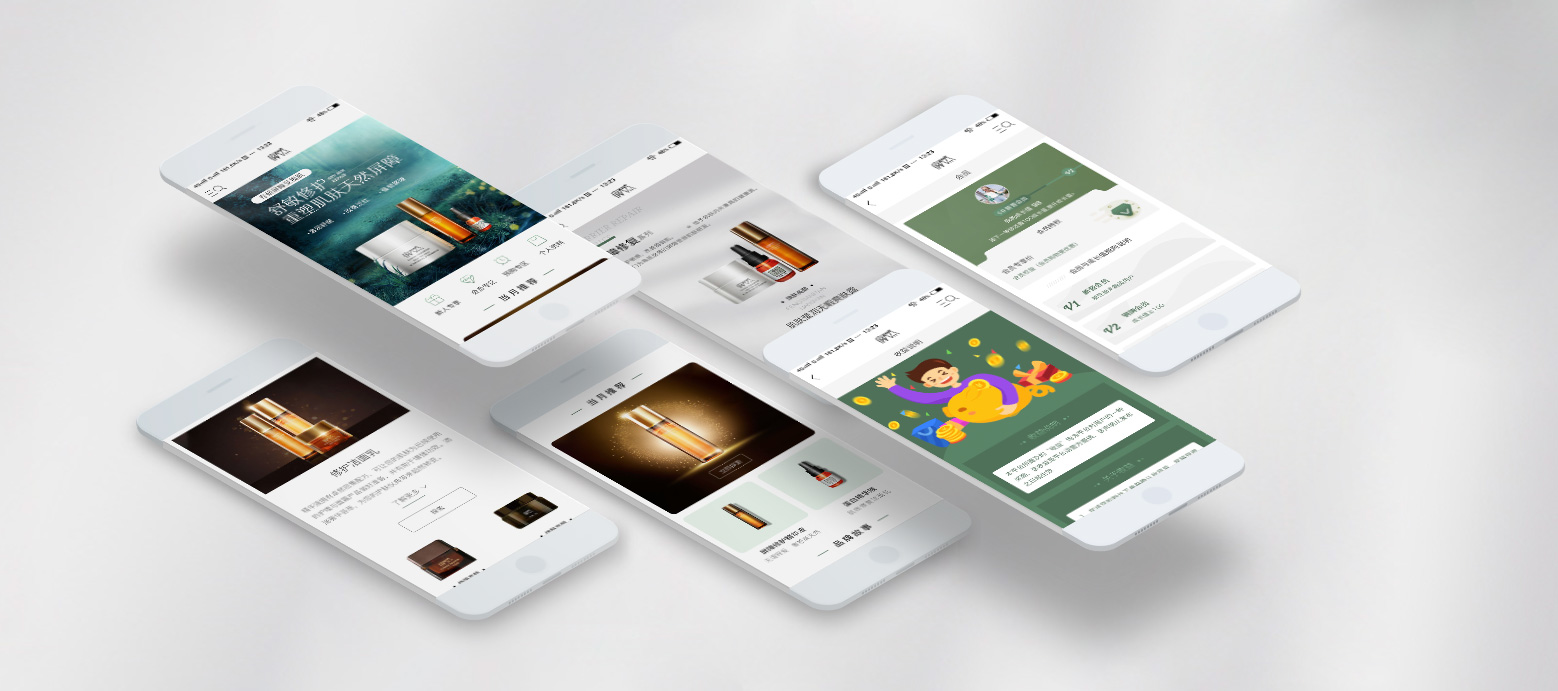
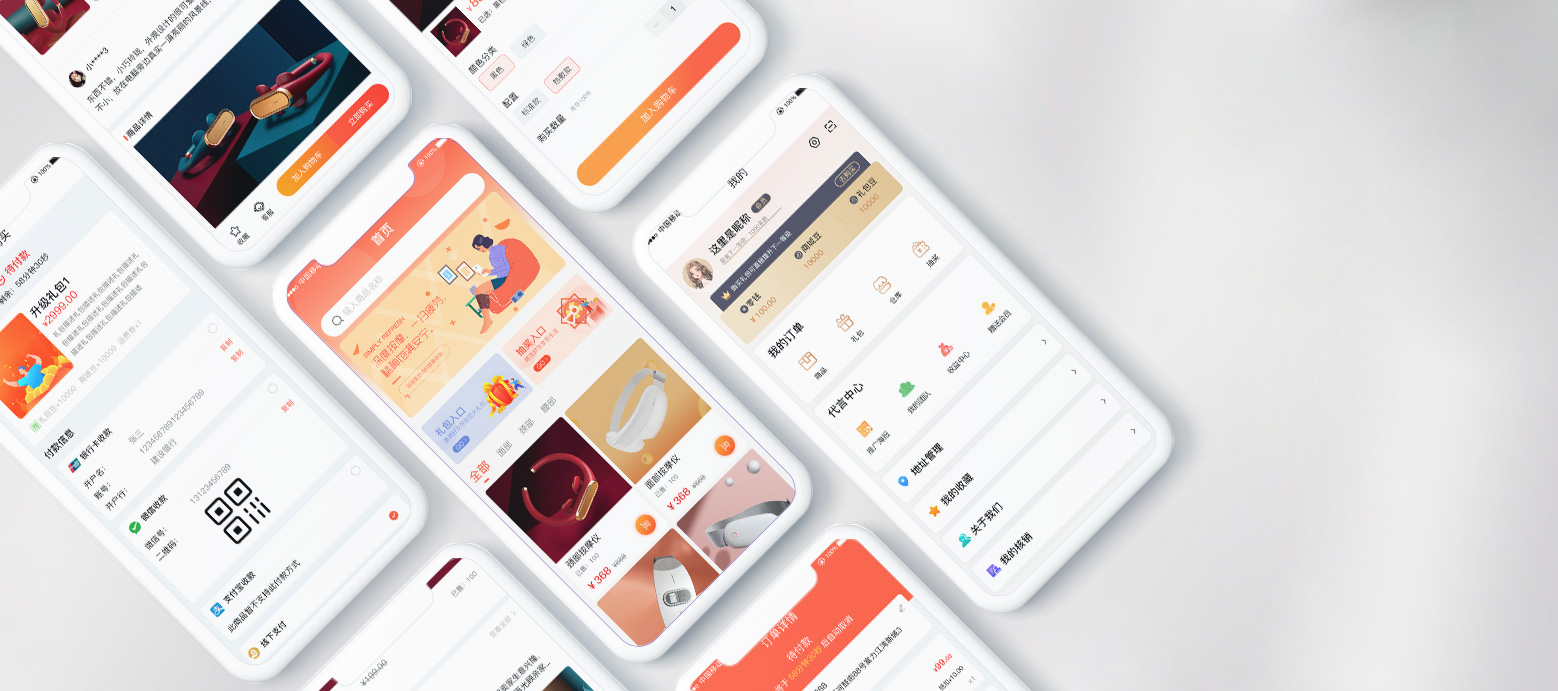
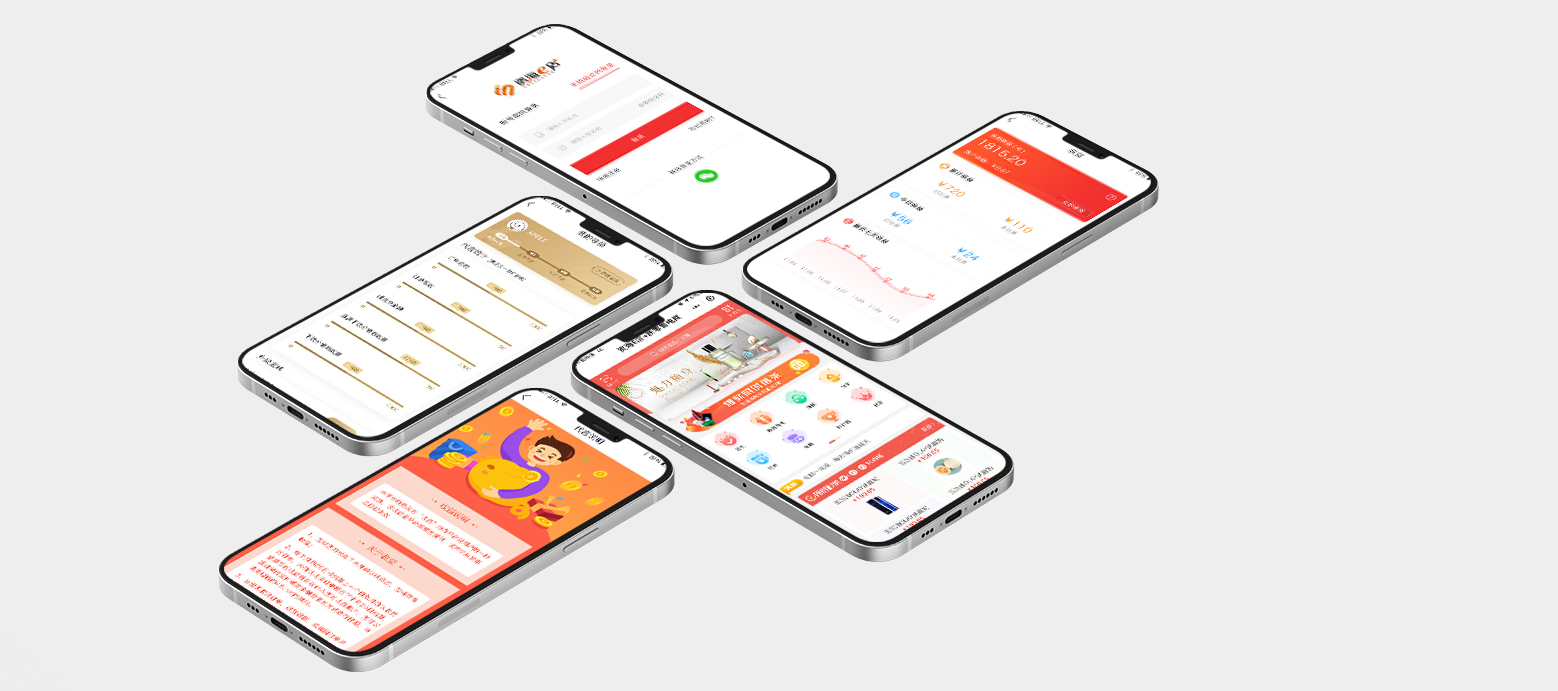

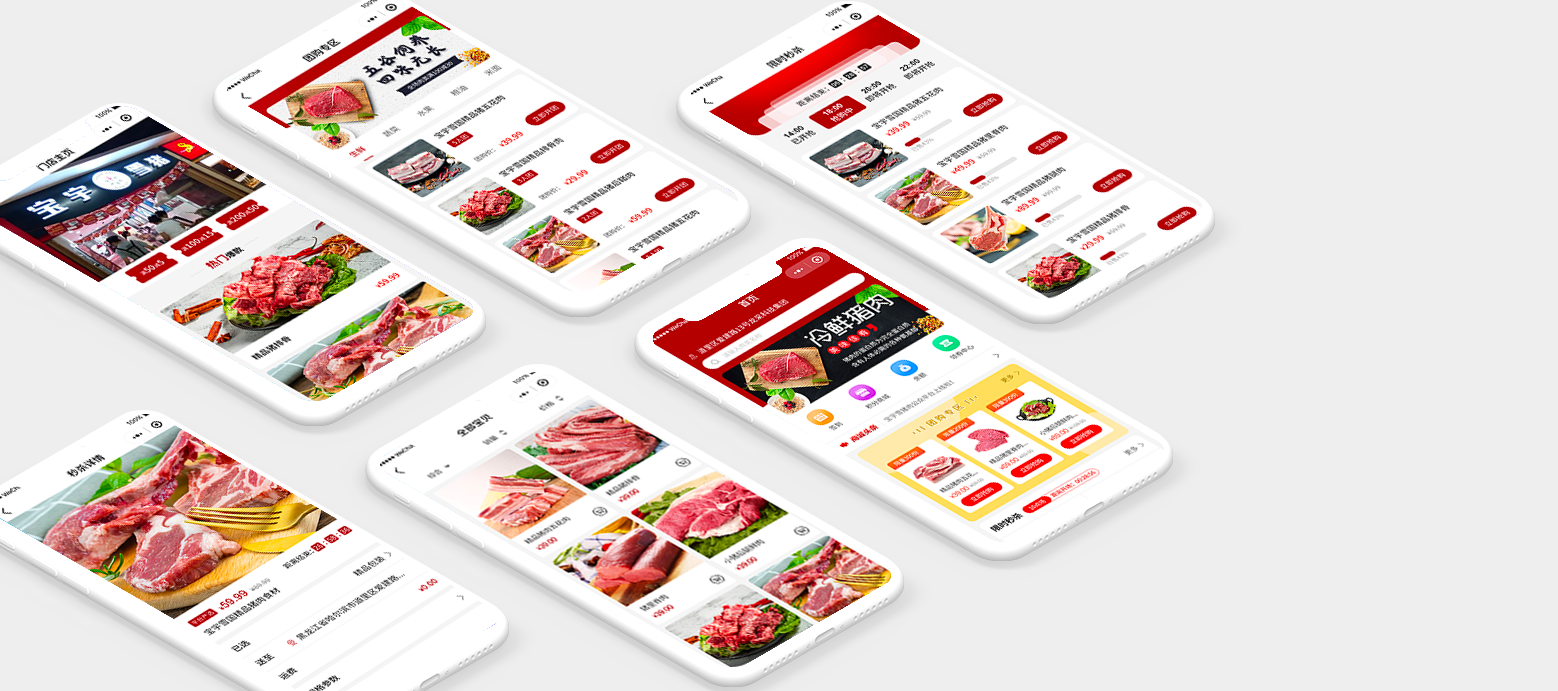

























































































































































































 遼ICP備09011618號(hào) 注冊(cè)人權(quán)利與責(zé)任
遼ICP備09011618號(hào) 注冊(cè)人權(quán)利與責(zé)任












 遼公網(wǎng)安備21030202000180號(hào) 注冊(cè)人權(quán)利與責(zé)任
遼公網(wǎng)安備21030202000180號(hào) 注冊(cè)人權(quán)利與責(zé)任